Video Recording of Test Execution is Easy
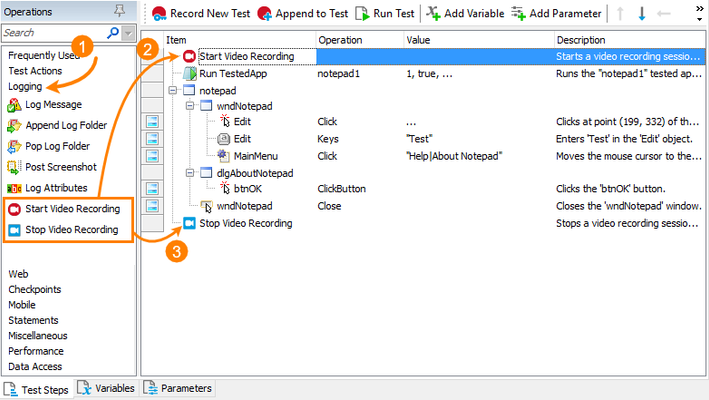
Hi folks! My name is Alexander Gubarev, and I'm one of the QA engineers who are responsible for the TestComplete quality. Today, I want to share the VideoRecorder extension for TestComplete with you, which I hope will be helpful in your job. This extension enables you to record videos for your automated tests running in SmartBear TestComplete or TestExecute. It records a video for your test runs helping you to check the test execution and to understand what happened in your system and in the tested application during the test run. All of us know, sometimes, it is really difficult to find the cause of issues that occur during nightly test runs. Videos can help you with this. The extension adds the VideoRecorder script object for starting and stopping video recording from your script tests, and the Start and Stop Video Recording keyword-test operations for doing this from keyword tests. Start using the VideoRecorder extension is easy - you simply need to install the extension on your computer and add call of it from TestComplete. INSTALL VIDEORECORDER 1. Download the VLC installer from https://www.videolan.org/. 2. Install the VLC media player on your computer. The installation is straight-forward. Just follow the instructions of the installation wizard. 3. Download VideoRecorder.tcx (it's attached to this article). 4. Close TestComplete or TestExecute. 5. Double-click on the extension and install it in TestComplete or TestExecute. USE VIDEORECORDER 1. In Keyword Tests Add the Start Video Recording and Stop Video Recording operations at the beginning and at the end of your test. You can find these operations in the Logging operation category. 2. In Scripts Use the VideoRecorder.Start() method to start recording and VideoRecorder.Stop() to stop it. Code example: //JScript function foo() { // Start recording with High quality VideoRecorder.Start("High"); //Do some test actions //…. //Stop recording VideoRecorder.Stop(); } Find the recorded video in your project folder – the link to it is located in the Test Log panel. FULL DOCUMENTATION https://github.com/SmartBear/testcomplete-videorecorder-extension/blob/master/README.md WANT TO IMPROVE THE VIDEORECORDER? We put this script extension on GitHub, so you can take part in its development. Feel free to make pull requests which can make this extension better: https://github.com/SmartBear/testcomplete-videorecorder-extension LATEST VIDEORECORDER VERSION Also, to make sure you have the latest version of the script extension, you can download VideoRecorder.tcx from the GitHub repository: https://github.com/SmartBear/testcomplete-videorecorder-extension/releases/latest9.5KViews11likes27Comments
Javascript for TestComplete
Dear community I just released a course for teaching Javascript to TestComplete testers interested in learning how Javascript works so that they can take advantage of this powerful scripting language inside of TestComplete. The course is purely Javascript to explain all the ins and outs. Everything you learn in the course is 100% usable in TestComplete. The course is free! https://github.com/TheTrainingBoss/Javascript-for-TestComplete Enjoy and good luck! -Lino3.8KViews10likes4CommentsTestComplete and (newly released) Zephyr Scale!!!
Update (February 4, 2022): Since my the post was created, some core changes have happened: 1. Atlassian's move to the cloud 2. Zephyr Scale cloud instance having a different set of API's & Bearer token authentication (to the example code snippets provided below) As such I am adding a link (https://community.smartbear.com/html/assets/ZScale.zip) to download the zipped .PJS file of the example integration. A couple things to change in the zipped file to make it work for you: Go to Project variables, find the one called cloud_token, and replace it with yours. (you can get it by clicking on your profile icon in jira, and by clicking zephyr scale api token) (it should say "REPLACE_ME" when you open the project variables page, just to make it extra clear) Go to the script routine called "utilities" Change the createTestRun_cloud function (line 22) project key to your Jira project key where your zephyr scale tests are. Change the createTestRun_cloud function "folderID" value (line 23) to your zephyr scale test folderId (this is optional; you can just delele/comment out this line as well) Change getTestCaseID function (lines 85-88) to match your Zephyr scale test case key (it should be something like JIRAKEY-T<123>) to match the names of the keyword tests that you have in testcomplete (in my case it was "login", "logout", "UI_Error", "UI_Warning", which mapped to KIM-T<123> etc.) Go to the script routine called "test11" change lines (36,37) optional - to match your jira user id (you can google how to find this) Change lines (104) to your jira project key Change lines (105) optional - to the zephyr scale test case folder id (you can google how to get this too) That should be enough to get started on this integration. The rest of the content below is a bit outdated (api's referenced are using server deployments, we no longer need to use the create_test_run item to create cycles -- I created an additional on start event handler to check if the current test is the "first" test item in your project run, etc.), but the general idea remains the same. ------------------------------------ Hi Everyone! Today I'm bringing news about Zephyr Scale (previously called TM4J, a Jira test management plugin that SmartBear acquired a few months ago). This is exciting because Zephyr Scale is considerably different fromZephyr for Jirain a number of ways. The biggest differentiation being that Zephyr Scale creates it's own table in your Jira database to house all of your test case management data and analytics, instead of issues of type "test". This means that you willnotexperience the typical performance degradation that you might expect from housing hundreds if not thousands of test cases within your Jira instance. Additionally, there's many more reports available:Upwards of 70(and it's almost "more the merrier" season so that's nice) Now how does this relate to TestComplete at all? Well, seeing as we don't have a native integration between the two tools as of yet (watch out in the coming months?), we have to rely on using Zephyr Scale's REST apiin order to map to corresponding test cases kept in Zephyr Scale's test library. I wanted to explore the option of having our TestComplete tests be mapped and updated (per execution) back to the corresponding test cases housed within Zephyr Scale by making use of event handlers and the REST api endpoints. To start, I created a set of test cases to mirror the test cases within Zephyr Scale and TestComplete: You will notice that I have a "createTestRun" KDT test within my TestComplete project explorer. This test case will make the initial POST request to Zephyr Scale in order to create a test run (otherwise known as a test cycle). This is done by using TestComplete's aqHttp object. Within that createTestRun kdt, I'm just running a script routine a.k.a run code snippet (because that's the easiest way to use the aqhttp object). The code snippet below shows the calls the snippet directly below is no longer needed for the integration. Instead, the onstart test case event handler (test11/def EventControl1_OnStartTestCase(Sender, StartTestCaseParams)) will go on to check to see if the currently started test case is the first test case in the project run (aka your test cycle), in which case it will create a new cycle for you. import json import base64 #init empty id dictionary id_dict = {} def createTestRun(): projName = "Automated_TestComplete_Run " + str(aqDateTime.Now()) #timestamped test cycle name address = "https://YOUR-JIRA-INSTANCE/rest/atm/1.0/testrun" #TM4J endpoint to create test run username = "JIRA-username" #TM4J username password = "JIRA-password!" #TM4J password # Convert the user credentials to base64 for preemptive authentication credentials = base64.b64encode((username + ":" + password).encode("ascii")).decode("ascii") request = aqHttp.CreatePostRequest(address) request.SetHeader("Authorization", "Basic " + credentials) request.SetHeader("Content-Type", "application/json") #intialize empty item list items= [] for i in range(Project.TestItems.ItemCount): #for all test items listed at the project level entry = {"testCaseKey":getTestCaseID(Project.TestItems.TestItem[i].Name)} #grab each tc key as value pair according to name found in id_dict items.append(entry) #append as a test item #building request body requestBody = { "name" : projName, "projectKey" : "KIM", #jira project key for the tm4j project "items" : items #the items list will hold the key value pairs of the test case keys to be added to this test cycle } response = request.Send(json.dumps(requestBody)) df = json.loads(response.Text) key = str(df["key"]) #set the new test cycle key as a project level variable for later use Project.Variables.testRunKey = key Log.Message(key) #output new test cycle key Within that snippet, you may have noticed an operation called "getTestCaseID()" and this was how I mapped my TestComplete tests back to the Zephyr Scale test cases (by name to their corresponding test id key) as shown below: def getTestCaseID(argument): #list out testcaseID's in dict format - this is where you will map your internal testcases (by name) to their corresponding tm4j testcases id_dict = { "login": "KIM-T279", "logout": "KIM-T280", "createTestRun": "KIM-T281", "UI_Error": "KIM-T282", "UI_Warning": "KIM-T283" } tc_ID = id_dict.get(argument, "Invalid testCase") #get testcase keys by name from dictionary above return tc_ID #output tm4j testcase ID Referring to the screenshots above, you will notice that the names of my KDT are the key values, where as the corresponding Zephyr Scale test id keys are the paired values within theid_dict variable. Now that we have a script to create a new test cycle per execution, which also assigns all test cases (at the project level) to the newly created test cycle, we just need to update that test run with the corresponding execution statuses for each of the test case to be run. We can do this by leveraging TestComplete's (onstoptestcase) Event handler in conjunction with Zephyr Scale's REST api. the Event handler: import json import base64 def EventControl1_OnStopTestCase(Sender, StopTestCaseParams): import utilities #to use the utility functions testrunKey = Project.Variables.testRunKey #grab testrun key from createstRun script tc_name = aqTestCase.CurrentTestCase.Name #grab current testcase name to provide to getTestCaseID function below tcKey = utilities.getTestCaseID(tc_name) #return testcase Key for required resource path below address = "https://YOUR-JIRA-INSTANCE/rest/atm/1.0/testrun/" + str(testrunKey) + "/testcase/" + str(tcKey) + "/testresult" #endpoint to create testrun w test cases username = "JIRA-USERNAME" #TM4J username password = "JIRA-PASSWORD!" #TM4J passowrd # Convert the user credentials to base64 for preemptive authentication credentials = base64.b64encode((username + ":" + password).encode("ascii")).decode("ascii") request = aqHttp.CreatePostRequest(address) request.SetHeader("Authorization", "Basic " + credentials) request.SetHeader("Content-Type", "application/json") #building requirest body; limited to pass,warning, and fail from within TestComplete. mapping to their corresponding execution statuses in tm4j comment = "posting from TestComplete" #default comment to test executions if StopTestCaseParams.Status == 0: # lsOk statusId = "Pass" # Passed elif StopTestCaseParams.Status == 1: # lsWarning statusId = "Warning" # Passed with a warning comment = StopTestCaseParams.FirstWarningMessage elif StopTestCaseParams.Status == 2: # lsError statusId = "Fail" # Failed comment = StopTestCaseParams.FirstErrorMessage #request body for each pertinent statuses requestBody = {"status": statusId,"comment":comment} response = request.Send(json.dumps(requestBody)) #in case the post request fails, let us know via logs if response.StatusCode != 201: Log.Warning("Failed to send results to TM4J. See the Details in the previous message.") We're all set to run our TestComplete tests while having the corresponding execution statuses get automatically updated within Zephyr Scale. Now a few things to remember: always include the "createTestRun" kdt as the topmost test item within our project run. this is needed to create the test cycle within Zephyr Scale (and there was no "onProjectStart" event handler so I needed to do this manually) make sure that within the script routine called gettestcaseID() that you have mapped the key value pairs correctly with the matching names and testcase keys. create a test set within the project explorer, for the test items you'd like to run (which has been mapped per the above bullet point, otherwise the event handler will throw an error). Now every time you run your TestComplete tests, you should see a corresponding test run within Zephyr Scale, with the proper execution statuses and pass/warning/error messages. You can go on to customize/parameterize the POST body that we create to contain even more information (i.e environment, tester, attachments, etc.) and you can go ahead and leverage those Zephyr Scale test management reports now, looking at execution efforts, defects raised, and traceability for all of the TestComplete tests you've designed to report back to Zephyr Scale. Happy Testing!7KViews9likes4CommentsRelease of two TestComplete Workshops on Github
It is my pleasure to release today two workshops on TestComplete, one for Keyword testing and one for Script testing, free of charge to the TestComplete community. I have been lucky enough to use the product for 18 years with great success and wanted to give something back to the community hoping that more testers will get the resources they need to adopt successfully this awesome product. https://github.com/TheTrainingBoss/TestComplete-Keyword-Workshop https://github.com/TheTrainingBoss/TestComplete-Scripting-Workshop I wanted to thanktristaanogre,Marsha_RandAlexKarasfor all their help and support to the community over the years. Go TestComplete! Happy Testing! -Lino2KViews9likes2CommentsAutomation Execution Report - Ready to Go!
Hi, I hope you guys aware of this thread Automation Execution Report So, I have completed scripting for the creating customized HTML using JavaScript. PFA TC project. Steps to access: ReportingFunctions.js having all the functions which is used to create HTML reports for Test case vise as well as high level report. Basically, After import the ReportingFunctions.js into your project. 1) At the starting point of your execution put below code ReportingFunctions.setLogsPath("C:\\AutomationLogs\\") ReportingFunctions.setExecutionStartTime(aqDateTime.Time()) 2) See the below steps for a test case i guess if see the functions name it is self-explanatory //Test Case #1 ReportingFunctions.setTestCaseExeStartTime(aqDateTime.Time()) ReportingFunctions.fn_createtestcasedescription("Module1","TestCaseID","TestCaseDescription","SYS"); ReportingFunctions.fn_createteststep(1,"Expe Result","Actual Result","Test Data",false); ReportingFunctions.fn_createteststep(2,"Expe Result","Actual Result","Test Data",false); ReportingFunctions.fn_createteststep(3,"Expe Result","Actual Result","Test Data",false); ReportingFunctions.fn_createteststep(0,"Expe Result","Actual Result","Test Data",false); ReportingFunctions.fn_createteststep(1,"Expe Result","Actual Result","Test Data",false); ReportingFunctions.setTestCaseExeEndTime(aqDateTime.Time()); ReportingFunctions.fn_createtestcaseduration() ReportingFunctions.fn_completetestcase() 3) In point of execution end put below code, ReportingFunctions.setExecutionEndTime(aqDateTime.Time()) ReportingFunctions.fn_generatehighlevelreport() The same flow workable function i have created in SampleCallMethod.js in the attached project. Please try this and let me know your feedback. sanjay0288Colin_McCraetristaanogre3.1KViews8likes0Comments
Launch Browser in Incognito/Private Mode
Thought of sharing the code in the community for launching browsers in their incognito modes. The function is parameterized such a way to run for the browsers Internet Explorer, Edge, Chrome and Firefox. Hope it will be useful for more people. function runIncognitoMode(browserName){ //var browserName = "firefox" //iexplore,edge,chrome,firefox if (Sys.WaitBrowser(browserName).Exists){ var browser = Sys.Browser(browserName); Log.Enabled = false // To disable the warning that might occur during closing of the browser browser.Close(); Log.Enabled = true // enabling the logs back } if(browserName=="edge"){ Browsers.Item(btEdge).RunOptions = "-inprivate" Delay(3000) Browsers.Item(btEdge).Run(); }else if (browserName=="iexplore"){ Browsers.Item(btIExplorer).RunOptions = "-private" Delay(3000) Browsers.Item(btIExplorer).Run(); }else if (browserName=="chrome"){ Browsers.Item(btChrome).RunOptions = "-incognito" Delay(3000) Browsers.Item(btChrome).Run(); }else if (browserName=="firefox"){ Browsers.Item(btFirefox).RunOptions = "-private" Delay(3000) Browsers.Item(btFirefox).Run(); } Sys.Browser(browserName).BrowserWindow(0).Maximize() }3.5KViews7likes3Comments
How to get cookies in Groovy scripts?
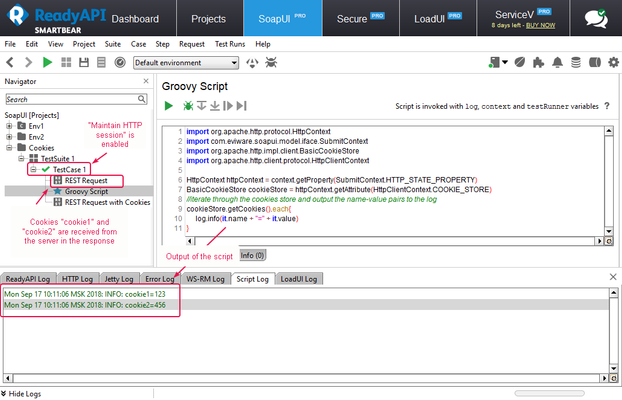
Hi Community, Let meshare an answer to the above question with you 🙂 If theSession optionis enabled, ReadyAPI maintains the HTTP session on the TestCase level automatically, which means that it storescookiesreceived from the server and sends them back in the subsequent requests to the same endpoint. If you need to get programmatic access to the stored cookies, you can use this Groovy script (it's applicable to ReadyAPI v.1.7.0 and later): import org.apache.http.protocol.HttpContext import com.eviware.soapui.model.iface.SubmitContext import org.apache.http.impl.client.BasicCookieStore import org.apache.http.client.protocol.HttpClientContext HttpContext httpContext = context.getProperty(SubmitContext.HTTP_STATE_PROPERTY) BasicCookieStore cookieStore = httpContext.getAttribute(HttpClientContext.COOKIE_STORE) //iterate through the cookies store and output the name-value pairs to the log cookieStore.getCookies().each{ log.info(it.name + "=" + it.value) } Example:3.6KViews7likes0CommentsHow to Parse a JSON Response Using Groovy (Examples!)
This code can be copied directly into a Groovy Script test step and run to demonstrate a few ways to get data from a JSON REST response: // Some Examples of How to Parse a JSON Response Using Groovy // set the example json response string (for a REST Request step assertion, use "def json = messageExchange.response.contentAsString") def json = '[{"firstName":"Bob","lastName":"Smith","uniqueId":146732,"thisIsAlwaysNull":null,"jobInfo":{"title":"","type":"Peon","code":42},"reviews":[{"date":"2017-06-01","type":"Regular","rating":"Adequate"},{"date":"2017-09-15","type":"Special","rating":"Other"}]},{"firstName":"Jack","lastName":"Jones","uniqueId":746381,"thisIsAlwaysNull":null,"jobInfo":{"title":"Big Boss","type":"Management","code":1},"reviews":[{"date":"2007-11-05","type":"Initial","rating":"Spectacular"}]},{"firstName":"Will","lastName":"Tell","uniqueId":574831,"thisIsAlwaysNull":null,"jobInfo":{"title":"Sweeper","type":"Peon","code":452},"reviews":[]}]' // parse json string using JsonSlurper - basically converts it to a groovy list def parsedJson = new groovy.json.JsonSlurper().parseText(json) // get data log.info " Count of people returned: " + parsedJson.size() log.info " Was Will's info returned (exists)? " + ( parsedJson.find { it.firstName == "Will" } != null ) log.info " Was Alice's info NOT returned (not exists)? " + ( parsedJson.find { it.firstName == "Alice" } == null ) log.info " First person's first name: " + parsedJson[0].firstName log.info " Index of person with ID 746381: " + parsedJson.findIndexOf { it.uniqueId == 746381 } log.info " Info for person with last name Tell: " + parsedJson.find { it.lastName == 'Tell' } log.info " Jack's ID: " + ( parsedJson.find { it.firstName == 'Jack' } ).uniqueId log.info " Jack Jones's job title: " + ( parsedJson.find { it.firstName == 'Jack' && it.lastName == 'Jones' } ).jobInfo.title log.info " All peon job type people's first names: " + ( parsedJson.findAll { it.jobInfo.type == 'Peon' } ).firstName log.info " Is Will's thisIsAlwaysNull null? " + ( ( parsedJson.find { it.firstName == 'Will' } ).thisIsAlwaysNull == null ) log.info " Will Tell's had this many reviews: " + ( parsedJson.find { it.firstName == 'Will' && it.lastName == 'Tell' } ).reviews.size() log.info " Bob's 2017-06-01 review rating: " + ( ( parsedJson.find { it.firstName == 'Bob' } ).reviews.find { it.date == '2017-06-01' } ).rating Hope this helps someone else!Solved21KViews7likes4Comments
Solution Script to Cleanup of Custom property values in the project
It is noticed that many were looking for a feature where users like to clean the custom property values. This eases to push the actual changes to repository (instead of just property values changes). Here is the context and feature request that was submitted long time ago and many were seeking this feature. https://community.smartbear.com/t5/ReadyAPI-Feature-Requests/Saving-without-property-values/idi-p/154115 Here I came up with a script which does exactly users are asking for. - In order to make the script flexible and dynamic, user need to add a project level property, say CLEAN_PROPERTIES and "false" as default value. - Though users like to clean property values, some might still wish to keep value for certain properties. To accomodate, users can add the property names which they don't want to clean up. Allows properties at test case, suite, and project levels. You don't have to do anything if you want to clean all properties. - The script has to be copied in the "Save Script" tab at the project level (double click project to see the same) - You don't have to run this script manually, this will automatically get triggered when project is saved on a condition that CLEANUP_PROPERTIES value is set true. Once it cleans the properties, the value is set to false to allow users not show the (repository) differences. This condition helps not to lose the property values while work in progress and project is saved. Once user changes to the project are complete and about to check-in the changes in to repositories, set the value to true and save. Now the project is ready the way users wanted. Here goes the script: /** * Project level's Save Script * Cleans up all the custom properties * If CLEAN_PROPERTIES value of project property is set to true * And save the project * */ def ignoreTestCaseProperties = [ ] def ignoreTestSuiteProperties = [ ] def ignoreProjectProperties = ['CLEAN_PROPERTIES'] def cleanProperties = { model, list -> model.properties.keySet().findAll{ !(it in list) } each { tProp -> model.setPropertyValue(tProp,'') } } if ('true' == project.getPropertyValue('CLEAN_PROPERTIES')) { project.testSuiteList.each { tSuite -> cleanProperties(tSuite, ignoreTestSuiteProperties) tSuite.testCaseList.each { tCase -> cleanProperties(tCase, ignoreTestCaseProperties) } } cleanProperties(project, ignoreProjectProperties) project.setPropertyValue('CLEAN_PROPERTIES', 'false') } Hope this is useful.Solved5.8KViews6likes18CommentsSharing is caring - how to modify xml files using ReadyApi
Modifying xml filesor simply working with xml strings might look difficult for a begginer so for those who need itI will try to break the whole thing into pieces so that it is easier to understand. Refering to nodes and attributes Let's say this piece of xml is stored in the file 'mijnFruits.xml' somewhere on your computer: <fruits> <apples> <apple color="red"/> <apple color="green"/> </apples> <oranges> <clementine> <mandarine> </oranges> <bananas/> <jabu-ticaba/> </fruits> If you would want to use a groovy script to identify a certain element, you'll first have to define a variable in which to parse the content: def xml = new XmlSlurper().parse("D:\\someFolder\\mijnFruits.xml") In order to refer to the 'clementine' node for instance, you would use: xml.oranges.clementine // For instance, the following will replace the node 'clementine' with 'tangerine' // xml.oranges.clementine.replaceNode { // tangerine '' // } Please note that while refering to any node, the root node (i.e. "fruits") is replaced by the variable in which the file is parsed (in our case 'xml'). That is why in our example we used 'xml.oranges.clementine' and not 'fruits.oranges.clementine' In order to refer to a node that has a certain attribute ( for instance <apple color="red"/> ), the syntax is as follows: // This will return a list will all the nodes 'xml.apples.apple' that have an attribute 'color' and the value 'red' xml.apples.apple.findAll{it.@color == "red"} // Hence, it is possible to check if such a node exists. For instance: //if (xml.apples.apple.findAll{it.@color == "red"}.size() == 0) // log.info("Such a node doesn't exist.") //else // log.info("Such a node exists.") If you want to refer to a node whose name contains dashes (example: 'jabu-ticaba') then the name must be placed inside single quotes like xml.'jabu-ticaba' // Example of node removing // xml.'jabu-ticaba'.replaceNode { } Practical examples Change an attribute value of a property import groovy.xml.XmlUtil import groovy.util.Node // Parse the content of the document and store it in the 'xml' variable def xml = new XmlSlurper().parse("D:\\someFolder\\web.config") // Change the attribute value for 'xxs-protection' xml.webApplication.'xss-protection'.@enabled = "false" // Construct a FileWriter object and assigns it to the variable 'writer' def writer = new FileWriter("D:\\someFolder\\web.config") // Write the changes to the file XmlUtil.serialize(xml, writer) // Close file writer.close() Add a new node import groovy.xml.XmlUtil import groovy.util.Node // Parse the content of the document and store it in the 'xml' variable def xml = new XmlSlurper().parse("D:\\someFolder\\web.config") // Add a node called 'conf' inside the <confs></confs> tags. The node will have 3 attributes (name, project and version) along with their corresponding values ('myName', 'myProj' and 'v0.0') xml.shortcutSection.shortcuts.appendNode { shortcut(name: "myName", project: "myProject", version: "v0.0") } // Construct a FileWriter object and assigns it to the variable 'writer' def writer = new FileWriter("D:\\someFolder\\web.config") // Write the changes to the file XmlUtil.serialize(xml, writer) // Close file writer.close() // The output will look like // <confs> // <conf name="myName" project="myProject" version="v0.0"/> // </confs> Add a more complex node import groovy.xml.XmlUtil import groovy.util.Node // Parse the content of the document and store it in the 'xml' variable def xml = new XmlSlurper().parse("D:\\mijn\\Web.config") // Add a more complex node (which contain more nodes or attributes) xml.'hibernate-configuration'.'session-factories'.appendNode { 'session-factory'(name: "test") { properties { property(name: "one hell of a property", value: "great of course") property(name: "another hell of a property", value: "great again of course") property(name: "avcsacsadsadsa", value: "asdsadsadasda") property(name: "asdsadsadas", value: "asdsadsadsa") property(name: "another hell of a property", value: "great again of course") } } } // Construct a FileWriter object and assigns it to the variable 'writer' def writer = new FileWriter("D:\\mijn\\Web.config") // Write the changes to the file XmlUtil.serialize(xml, writer) // Close file writer.close() Remove a node import groovy.xml.XmlUtil import groovy.util.Node // Parse the content of the document and store it in the 'xml' variable def xml = new XmlSlurper().parse("D:\\mijn\\Web.config") // Remove a node xml.shortcutSection.replaceNode { } // this removes the shortcutSection node along with its containments // Construct a FileWriter object and assigns it to the variable 'writer' def writer = new FileWriter("D:\\mijn\\Web.config") // Write the changes to the file XmlUtil.serialize(xml, writer) // Close file writer.close() Remove a node that contains a certain attribute import groovy.xml.XmlUtil import groovy.util.Node // Parse the content of the document and store it in the 'xml' variable def xml = new XmlSlurper().parse("D:\\mijn\\Groovy projects\\Web.config") // Delete a node that has a certain given attribute xml.'hibernate-configuration'.'session-factories'.'session-factory'.findAll{it.@name == "myName"}.replaceNode { } // Construct a FileWriter object and assigns it to the variable 'writer' def writer = new FileWriter("D:\\mijn\\Groovy projects\\Web.config") // Write the changes to the file XmlUtil.serialize(xml, writer) // Close file writer.close() Replace a node import groovy.xml.XmlUtil import groovy.util.Node // Parse the content of the document and store it in the 'xml' variable def xml = new XmlSlurper().parse("D:\\mijn\\Groovy projects\\Web.config") xml.configSections.replaceNode { noMoreConfigSection '' } // Construct a FileWriter object and assigns it to the variable 'writer' def writer = new FileWriter("D:\\mijn\\Groovy projects\\Web.config") // Write the changes to the file XmlUtil.serialize(xml, writer) // Close file writer.close() // The result would be that the configSections node i.e. // <configSections> // <section ...> // <section ...> // </configSections> // would be replaced by <noMoreConfigSection/>6.2KViews6likes3Comments