How attach files after an automated execution
A few weeks ago we purchased Zephyr Scale for Jira Cloud. I know how it works on Server version and now I implemented the cloud version for execution test, there I don't have any issues, however after an execution I can't upload files like the server version, where the url is like this "/testresult/{testResultId}/attachments" to post a file from a previous result. I'm trying to figure out how I can upload files, but checking the API information I could use "/automations/executions/custom" and I'm getting the following response: { "errorCode": 400, "message": "Couldn't find any mapped test cases", "status": "Bad Request" } How I can resolve this? Are there any alternatives for cloud version to accomplish this? In this place for Server version I was able to upload files after an execution with"/testresult/{testResultId}/attachments", for example:2.4KViews0likes3Comments
ReadyAPI and TestEngine with Zephyr Scale
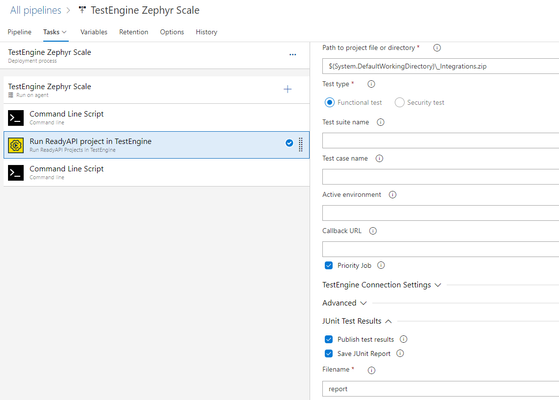
In this post, we are going to talk about using some of the SmartBear API testing tools and writing the results in an automated fashion to Zephyr Scale. But first let's take a step back and discuss a general approach of using testing tools with test management tools. At a manual level, when creating simple Multi-Protocol API tests, we might use a lighter weight tool like SoapUI Open Source, a great tool for quick and basic functional and performance API tests. After we trigger the test manually, we as humans would parse the report for any details on the test run, and to track it would update a spreadsheet, testcase in Jira, but somewhere. This sequence is important to note for when we start to advance to an automated workflow. Now let's talk about automating this process. We execute our API tests in an ephemeral environment, publish the results to a relative location, and then pass those results from that relative location to a test management platform. It is quite simple. In this workflow it tends to be easier to use a tool that has native integrations into CI platforms like Jenkins and Azure Dev Ops, that make managing our executions in these ephemeral environments much easier. Here, ReadyAPI, or TestEngine is the clear choice as they both seamlessly integrate into any CI-CD system and have native integrations into Jenkins, Azure, and many more. Now that sequence I mentioned earlier is very important. We will execute our API tests, and then pass the results into Zephyr Scale as step 2 in the pipeline. Here is a look at a scripted pipeline approach, note that there is freestyle job options available in Jenkins too. ReadyAPI Jenkins Plugin: https://support.smartbear.com/readyapi/docs/integrations/jenkins.html TestEngine Jenkins Plugin: https://support.smartbear.com/testengine/docs/admin/jenkins.html node { stage('Run API Tests') { // Run the API Tests using ReadyAPI or TestEngine stage('Pass Results') { //Pass Results to Zephyr Scale } } Now we need to be a little more specific with the 'Run API Tests' Stage. Above I mention when we run our API Tests in an automated fashion, we need to write the results to a relative location so that we can then send those results to Zephyr Scale from that location. Both ReadyAPI and TestEngine allow us to write results to locations as part of the command-line or native integrations. I will show command- line options for ReadyAPI and UI native integration for TestEngine but both options are available for both tools. Starting with ReadyAPI, testrunner CLI, the -f and -F flags represent the directory we are writing to, and the report format, respectively. ReadyAPI offers reports in PDF, XLS, HTML, RTF, CSV, TXT and XML, but the automation recommendation would be to pass results in the Junit-XML option. At a basic level we need this: testrunner.bat [optional-arguments] <test-project> And we need to specify -f and -F testrunner.bat -f<directory> -F<args> <test-project> and with -f requiring a relative directory, that can change based on the CI system. I will use Azure Dev Ops for both my examples here. In Azure I pull my test cases from the $(System.DefaultWorkingDirectory), which contains my git repo. In Azure I publish results to the $(Common.TestResultsDirectory) An example full command would look like this: "C:\Program Files\SmartBear\ReadyAPI-3.40.1\bin\testrunner.bat" -r -a -j -f$(Common.TestResultsDirectory) "-RJUnit-Style HTML Report" -FXML "-EDefault environment" "$(System.DefaultWorkingDirectory)/" With TestEngine it's very similar, but I am highlighting it through the native integration, note the publish test results and save Junit report option enabled below: Now lastly, we need to send the results to Zephyr Scale from the pipeline, before our release is over. I think it's easiest with the Zephyr Scale API: https://support.smartbear.com/zephyr-squad-cloud/docs/api/index.html along with the Auto-Create Test Case option to true. The command below is a basic example, and replica of the one seen in the Azure Pipeline screenshot. curl -H "Authorization: Bearer Zephyr-Scale-Token-Here" -F file= Relative-Location-of-Report-Here\report.xml;type=application/xml "https://api.zephyrscale.smartbear.com/v2/automations/executions/junit?projectKey=Project-Key-Here&autoCreateTestCases=true" After you modify the API token, Relative location, and project key you are good to run the pipeline. When we jump to Jira, we can see inside Zephyr Scale that the results are populating. Even with transactional Data on the failed test steps.1.5KViews0likes0CommentsTestComplete with Zephyr Scale
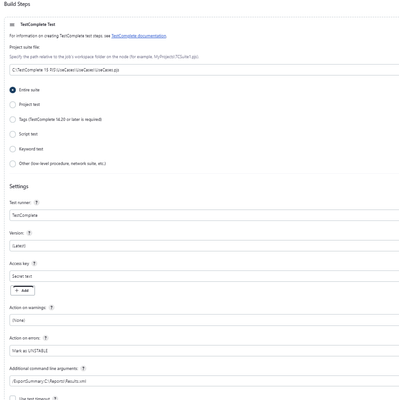
In this post, we are going to talk about SmartBear’s UI testing tool, TestComplete, and writing the results to Zephyr Scale in an automated fashion. When we think about using TestComplete with any test management tool, it can really be accomplished in two ways: Natively inside TestComplete or integrating with some CI-CD system. When we are using Zephyr Scale, both ways will utilize the Zephyr Scale REST API. When we link to Zephyr Scale natively from TestComplete, it is a script heavy approach. An example of that can be found here. Today we are going to go into detail about using TestComplete, with a CI-CD system, and sending the results to Zephyr Scale. Now let’s talk about automating this process. The most common way to automate triggering TestComplete tests is through one if its many integrations. TestComplete can integrate to any CI-CD system as it has Command Line options, REST API options, and many native integrations like Azure Dev Ops or Jenkins. The use of a CI-CD system makes managing the executions at scale much easier. The general approach to this workflow would be a two-stage pipeline something like: node { stage('Run UI Tests') { // Run the UI Tests using TestComplete stage('Pass Results') { //Pass Results to Zephyr Scale } } First, we trigger TestComplete to execute our tests somewhere. This could be a local machine or a cloud computer, anywhere, and we store the test results in a relative location. Next, we use a batch file (or alike) to take the results from that relative location, send them to Zephyr Scale. When executing TestComplete tests, there are easy ways to write the results to a specific location in an automated fashion. We will look at options through the CLI as well as what some of the native integrations offer. Starting with the TestComplete CLI, the /ExportSummary:File_Name flag will generate a summary report for the test runs, and save it to a fully qualified or relative path in Junit-XML structure. At a basic level we need this: TestComplete.exe <ProjectSuite Location> [optional-arguments] So something like this: TestComplete.exe "C:\Work\My Projects\MySuite.pjs" /r /ExportSummary:C:\Reports\Results.xml /e The /ExportSummary flag can be stored in a relative or fully qualified directory. We could also use one of TestComplete’s many native integrations, like Jenkins and specify in the settings where to output results: Now that our TestComplete tests are executing, and the results are writing to a relative location we are ready for stage 2 of the pipeline, sending the results to Zephyr Scale. So now let’s send our results to Zephyr Scale. I think the easiest option is to use the Zephyr Scale API, and the Auto-Create Test Case option to true. The command below is a replica of what you would use in a batch file script in the pipeline. curl -H "Authorization: Bearer Zephyr-Scale-Token-Here" -F file= Relative-Location-of-Report-Here\report.xml;type=application/xml "https://api.zephyrscale.smartbear.com/v2/automations/executions/junit?projectKey=Project-Key-Here&autoCreateTestCases=true" After you modify the API token, relative location, and project key you are good to run the pipeline. The pipeline should look something like this: After we run the pipeline let’s jump into Jira to find to confirm the results are populating. Even with execution data: Also, with transactional data to analyze the failed test steps:1.4KViews0likes0Comments
Data-driven testing - how to use non-dataset data in Zephyr
Hi, Could you please advice on how I can use other data source then Zephyr data-set (eg csv, excel sheet, xml, SQL database) as input data for my manual test cases? The manual describes that it is possible, however this doesn't explain how it can be achieved. "Data-driven testing (DDT) is an approach to test design where the test data (input and output values) is separated from the actual test case. The test data can be stored in one or more central data sources and shared across different test cases. By storing your test data in a central repository (local storage, Excel spreadsheet, XML file, or SQL database), you can run the same test with a new set of data each time, avoiding redundant design and execution of repetitive tests cases. Toward the end of the test cycle, you can store test data to provide a clear audit trail of what was and wasn’t covered by a test." https://support.smartbear.com/zephyr-scale-server/docs/test-cases/create/ddt/about.html Regards PiotrSolved1.7KViews0likes4Comments
server version: uploading test results to Zephyr Scale via the automation API
Hello! I'm using Zepyhr Scale Server and I would like to upload to Zephyr the results of my automation testsuite made with pytest. I've tried this POST request: post(url="https://{my-jira-host}/rest/atm/1.0/automation/execution/{projectKey}", auth=({my_username}, {my_password}), files={"file":open("test_results.zip","rb")}) but it doesn't work because the response is "errorMessages":["Invalid Custom Format JSON file"]}'. I'm uploading a zip file containing one xml file generated with pytest --junitxml=output/junitxml_report.xml as it's explained herehttps://support.smartbear.com/zephyr-scale-cloud/docs/test-automation/pytest-integration.html I've tried to make the same request with an API client (Postman) and the error is"InvalidZIPfile", even if I fail the authentication with a wrong username or even if I upload the xml file only. Maybe someone does the same thing and could help me? I'm a newbie 🙂 thanks!Solved6.3KViews0likes10CommentsAutomatic Traceability Links in Zephyr Scale Cloud
Hi everyone, right now, we are using Zephyr Scale Server in our company but we are (as a lot of users/companies probably are) evaluating the move to the cloud app. Now, regarding the traceability in the cloud app, I'm at a bit of a loss and maybe those, that already use the cloud app, can shed some light on this. Recently, we got a test account for the cloud app of Jira including Zephyr Scale and I have been looking into the differences between server and cloud. One thing that is very important to us as a financial service provider in Germany is the traceability between issues, test cases and test executions. I can link test cases to issues and link issues to test executions, just as I can do in the server app. In server, if you execute a test case covering an issue and you link another issue to the test execution, you automatically get the link between issue 1 and 2 (e.g. requirement and defect) shown in the respective issues. This does not seem to happen in cloud. All I get is the link to the impacted test execution. This means, that to trace the connection between requirement and defect I have to do a lot more work (clicks) than in server. For example, a defect is created from a test execution in Zephyr and assigned to a developer. He/she opens the issue and wants to know, which requirement is impacted by this defect. Since only the impacted test execution is shown in the defect, he/she has to click that, then click the corresponding test case and then go to the traceability tab of that test case to finally be able to get to the requirement. Also, I do not have the option to configure Zephyr in such a way, that test cases (including their execution history) are automatically linked to created defects (as 'blocked') which we use regularly to better manage re-tests of defects. So the question for all you cloud users out there. Am I missing something? Or is this really a limitation of the cloud app? Sorry for the long post and thanks in advance for any info. 😉 Cheers Josh1.6KViews0likes3Comments
Zephyr Scale - Cucumber and Junit test results metadata
I am on Zephyr Scale Server. Details of automated tests results that gets sent to Zephyr Scale does not give a lot of meaningful data. Iam following Smartbear's integration guide to send results up to Zephyr Scale [https://support.smartbear.com/zephyr-scale-server/docs/test-automation/integrations/bamboo.html] i.e. by sending zippedcucumber.json or junit files to the appropriate endpoint. Problems : 1. All automated runs creates new cycle with the name "Automated build" always. It's hard to differentiate builds when working with multiple projects in parallel. I should be able control the created cycle name. 2. Details of environment, version etc are not updated from the results file 3. Details of failure are not captured in Zephyr scale even though it's on the the result file. The test simply fails without giving details of why it failed. It need to be able to update as many meaningful information as possible to the failed tests in Zephyr Scale I am aware that Zephyr apis [https://support.smartbear.com/zephyr-scale-server/api-docs/v1/]allows us to build a bespoke solution to fix the above problems. However, i am cautious of building additional code as wrappers and would like to use out of the box solution as much as possible for maintenance and cost purpose. What is the recommended automated test reporting practice from Zephyr Scale team?955Views0likes0Comments
is there any Zephyr Gadget that support custom fields?
just checked the source that describesGadgets ofZephyr: https://support.smartbear.com/zephyr-scale-cloud/docs/reports-and-analysis/using-gadgets.html is there any Zephyr Gadget that support custom fields? 2nd question where to see all the Gadgets?1.3KViews0likes3CommentsHow to organize best Zephy Scale with multiple projects and a central Testing Team
Hi everyone We have multiple Products, which are related to each other (SW and HW). Therefore, we have multiple Jira Projects. Every project team has also it's tester who writes Test Cases and is responsible for the Test Automation etc. In order to Tests all the products together, we have a centralized Testing Team, which makes all the System Tests. What is the best way to organize the Test Management with Zephyr Scale or what possibilities does Zephyr Scale offer for this case? My idea was * Make a new Jira Project which contains all the Test Cases from all Jira Projects and link them to the corresponding Jira Projects * Every Test Plan, Test Cycle will be executed in this Test Project. * However, there will tests where the System Test Team is not needed. Where should we put this Test Cases (Jira Test Project or the Product Jira Project? ** Is it possible to share or link Test Cases among multiple Jira Projects? Best AleksSolved2.6KViews0likes4Comments