ReadyAPI- download a textfile from a URL with groovyscript
Hello,
I have looked at a dozen of possibilities online to download a textfile from a website, but none is actually OK for my case.
What I need to do:
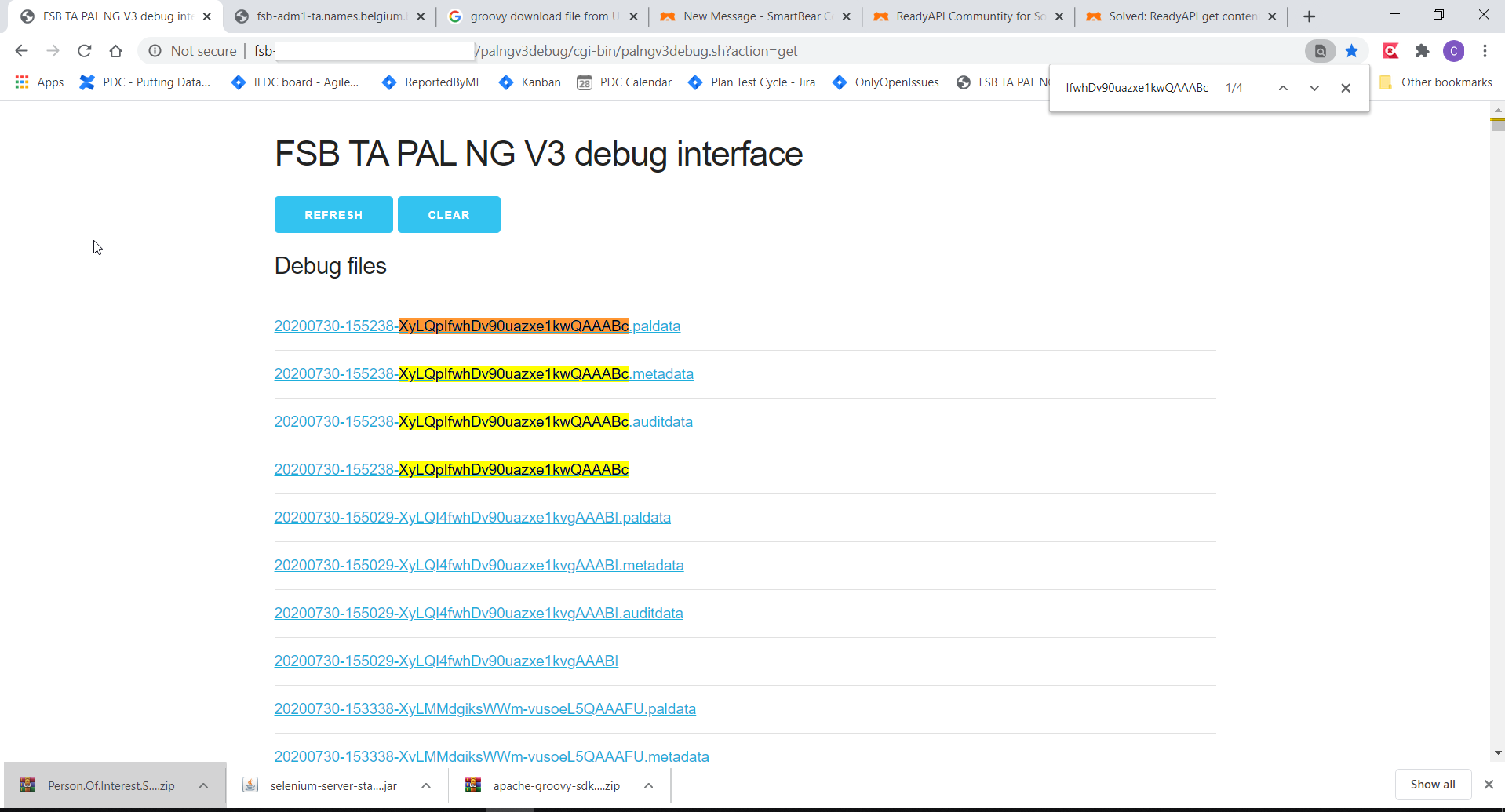
Go to the website that contains a bunch of logfiles (extension = paldata but actually can be saved as textfile)
search for a file with an ID in the string equal to, let's say,
XyLQpIfwhDv90uazxe1kwQAAABc
e.g. 20200730-XyLQpIfwhDv90uazxe1kwQAAABc.paldata
Open the file and read it.
Search for "fsbTransactionid".
If it's not present --> error message
<Response-code>404</Response-code>
if it's present read it and stash it in a variable
I would like to do that for different ID's in the file.
Now, as I found a lot "BuilderHTTPs" methods, I/O Read and Write methods that I've tried, it seems that I'm not able to handle the total picture. and the installation of a standalone selenium didn't work for me neither. (cfr. to another post of mine)
Does somebody have another idea please?
nmrao ? groovyguy ? NBorovykh Anastasia ?
Thanks in advance
AboveAndBeyond
{kind=link}
Hi all,
Thanks for your help. and..... I've managed to do this with all of your suggestions 😉 I resolved this issue like this:
Create testcase X, I've called it "CheckHeaders".
In this testcase setup this framework:
* REST Request
* Groovy script1 (I've called it 'GetIDsFromRawRequest)
* Delay
* HTTP request1 (I've called it GetFileFromE2E)
* Groovy script2 (I've called it Get FileFromURL)
* HTTP request2 (I've called it GetFile Content)
Explanation:
REST Request: This request is pointing to the REST Request that you want answers from. This request will give you the ID's you're searching for.
Groovy script1:
import groovy.json.JsonSlurper //cfr. https://community.smartbear.com/t5/SoapUI-Pro/ReadyAPI-get-RawResponse-with-groovyscript/m-p/205378#M46921 def jsonSlurper testRunner.testCase.getTestStepByName("REST Request").testRequest.response.responseHeaders.each { if (it.key == "X-BOSA-ServiceInfo") jsonSlurper = new JsonSlurper().parseText(it.value) } def applicationID = jsonSlurper.ApplicationID def fsbTransID = jsonSlurper.fsbTransactionId def providerID = jsonSlurper.ProviderID def backendTime = jsonSlurper.BackendTime assert applicationID != "" : "applicationID is blank" assert applicationID != null : "applicationID is null" assert fsbTransID != "" : "applicationID is blank" assert fsbTransID != null : "applicationID is null" assert providerID != "" : "applicationID is blank" assert providerID != null : "applicationID is null" assert backendTime != "" : "applicationID is blank" assert backendTime != null : "applicationID is null" testRunner.testCase.setPropertyValue("appId",applicationID.toString()) testRunner.testCase.setPropertyValue("fsbTransId",fsbTransID.toString()) testRunner.testCase.setPropertyValue("providerID",providerID.toString()) testRunner.testCase.setPropertyValue("backendTime",backendTime.toString()) log.info applicationID log.info fsbTransID log.info providerID log.info backendTimeDelay: this speaks for itself. In my case it takes a while before the logfiles are created and can be downloaded from the E2E.
HTTP Request1:
This request points to the website where you want to download the files. This is a "GET" request.
Groovy script2:
import groovy.xml.XmlSlurper import groovy.json.JsonSlurper def getID = testRunner.testCase.getPropertyValue("fsbTransId") log.info getID //read the http body without parsing as text. without headers def response = context.expand( '${GetFileFromE2E#Response}' ) log.info response //read text as xml file, then with jsonparser find folder if(response.contains(getID)) { log.info "file found" } def xml = new XmlSlurper().parseText(response) //lookup the pageproperty where the file is stashed and have a look how the webpage was //created. follow the div's and all its elements in it. xml.body.div[0].div[0].div[1].table.'*'.each { if (it.text().contains(getID) && it.text().contains(".paldata")) { log.info "Found it!!: surf to: http://fsb-adm1-ta.names.belgium.be:XXXX/palngv3debug/download/" + it.text() def url = "http://fsb-adm1-ta.names.belgium.be:XXX/palngv3debug/download/" + it.text() //put the url on testCase level in a parameter testRunner.testCase.setPropertyValue("url", url) } } //create other step to send the url, in that step assert that all id's are presentHTTP Request2:
For this request use as Endpoint the parameter that you've saved on testcase level as such: ${#TestCase#url}
Add a script assertion to this request to get and compare the parameters.
import com.eviware.soapui.support.XmlHolder import groovy.json.JsonSlurper def holder = new XmlHolder( messageExchange.responseContentAsXml ) def nodegetID = holder.getNodeValue( "//data[1]/RequestHTTPHeader-data[1]/fsbTransactionId[1]" ) //get results from ResponseHTTPHeader up to ServiceInfo def nodeServiceInfo = holder.getNodeValue( "//data[1]/ResponseHTTPHeader-data[1]/ServiceInfo[1]" ) log.info nodeServiceInfo //use a jsonSlurper to read out the content of ServiceInfo def jsonSlurper = new JsonSlurper() //parse the response def parsedJson = jsonSlurper.parseText(nodeServiceInfo) log.info "ProviderID: " + parsedJson.ProviderID def getproviderID = parsedJson.ProviderID def getbackendTime = parsedJson.BackendTime def getapplicationID = parsedJson.ApplicationID //get the parameters from TestCase level def getID = context.expand( '${#TestCase#fsbTransId}' ) def providerID = context.expand( '${#TestCase#providerID}' ) def backendTime = context.expand( '${#TestCase#backendTime}' ) def appId = context.expand( '${#TestCase#appId}' ) //assert assert nodegetID != null assert nodegetID == getID assert providerID != null assert providerID == getproviderID assert backendTime != null assert backendTime == getbackendTime assert appId != null assert appId == getapplicationIDAnd for me, this does the job! 🙂
Happy testing 😉 !