How do you structure workflow tests
Hello,
I am just curious how others create their workflow tests in TestComplete and to learn if what I am doing is the most efficient way.
What I have been doing is -
1. Create various scripts and in each script I add different functions which I will need for my tests
2. In these functions I add user parameters. I don't hardcode parameter values in these scripts and functions
3. Then, in the project page, I create a new group. This group is basically my test which will contain all the test steps
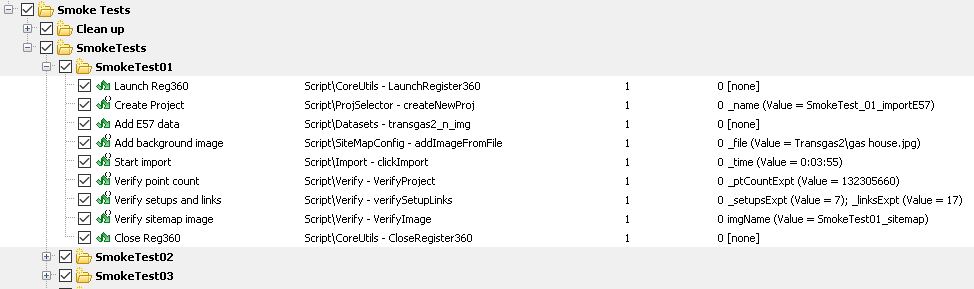
4. Under this group, I create various test items. For each test item, I call a function from a script and then pass the parameter values in the 'Parameters' column. So each group/test is a collection of test items and each test item is calling a function from one of my global scripts and passing the user paramter values (screenshot attached)
I recently saw another way to create tests where they had a global script with functions and parameters. But they do not create test items in the project page. Instead, they create separate test scripts and each of this test script contains a function; and this function itself is a test workflow i.e. the function inside the test script is an entire workflow where it calls the functions from the global scripts and hardcodes the paramter values inside these functions.
I always thought that creating workflows under a function with hardcoded input values was not efficient since it is not very re-usable and defeats the purpose of a function. But maybe I am wrong.
I also thought that a function should always be a re-usable building block for tests and not be a test itself. Is that a correct to say? Please correct me if I am wrong. Thank you!
What are your thoughts about both the ways? Or, if you could share, how do you create your tests. Thanks!
Stay safe everyone!
Regards,
Sam
{kind=link}