Yes, I think I know what the problem is. Our starting points are different -- it is most likely that your corrupted file encoding is different than what mine was.
Mine was UTF-16 (LE). (LE = Little Endian). See attached file for sample (yellow highlighting indicates encoding).
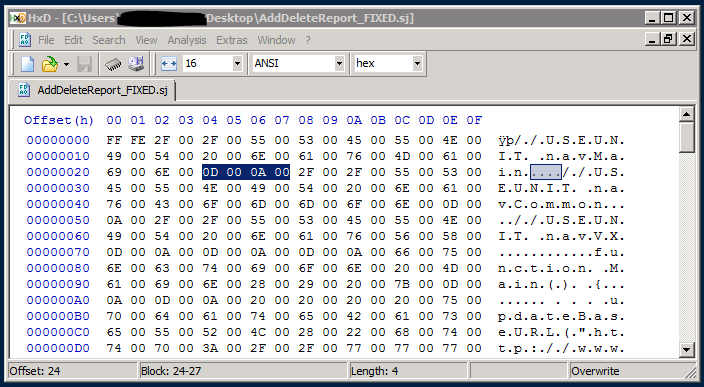
If you look at the first 2 or 3 bytes of your original corrupted file in HxD, it's probably either UTF-8 (hex=EF BB BF), or UTF-16 (BE) (hex=FE FF). It's possible, but very unlikely, that you have one of the other 5 UTF encoding types.
From my screenshot, and for my encoding type, the actual Find/Replace values should have been to find "0D 00 0D 0A 00" and replace with it with "0D 00 0A 00". (sorry, in my original post, it worked for me, but was not 100% accurate because it was offset by 1 byte). Please compare both screenshots to see the Find/Replace difference.
However, based on your encoding, it will probably require a slightly different treatment. But without seeing the hex values, I can't tell you what the Find/Replace values should be.
So I would suggest to post a screenshot of the first few lines of your original corrupted file in HxD, or the original file itself (but be careful of propritary content as this is a public forum). Then I can tell you what the Find/Replace should be for your files.
Regards,
Brian
{kind=link}
{kind=link}
{kind=link}
{kind=link}